Golang数据类型、数组和切片-Golang夯实基础第三天
-
nil空值指针
-
类型转换
Go语言只有强制类型转换,没有隐式转换基本格式:
T(表达式)T表示对应要转为的数据类型func Test_B_11(t *testing.T) { var a int = 10 var b string = "ABC" var c string = "哇哈哈WHH" a2 := float32(a) b2 := []byte(b) c2 := []rune(c) fmt.Printf("%v,%T\n", a2, a2) fmt.Printf("%v,%T\n", b2, b2) fmt.Printf("%v,%T\n", c2, c2) }10,float32 [65 66 67],[]uint8 [21703 21704 21704 87 72 72],[]int32 -
字符串相关操作
-
多行字符串
使用
`反引号可以换行func Test_B_0(t *testing.T) { str := `2023 xxcheng daydayup ` fmt.Println(str) }
-
求长度
func Test_B_1(t *testing.T) { str := "ABC中国China" str2 := "小小程日记!" str3 := "12345678" fmt.Println(len(str), len(str2), len(str3)) }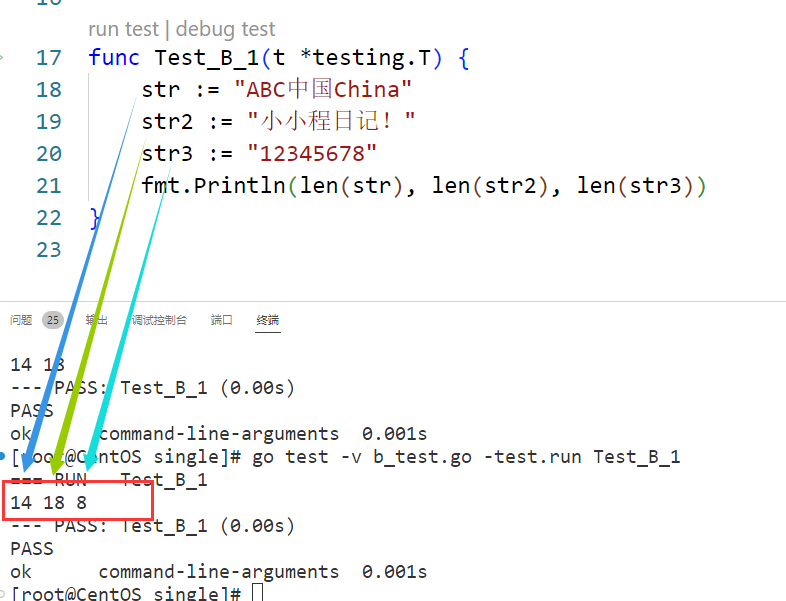
Go语言的字符串都以UTF-8格式保存,每个中文占用 3 个字节 -
拼接字符串
func Test_B_2(t *testing.T) { str := "小小程日记" str2 := "笔记分享" a := str + "-" + str2 b := fmt.Sprintf("%s-%s", str, str2) fmt.Println(a) fmt.Println(b) }小小程日记-笔记分享 小小程日记-笔记分享 -
分割字符串
使用
strings.Split函数分割func Split(s, sep string) []stringfunc Test_B_3(t *testing.T) { str := "ABC-XYZ-XXCHENG" str2 := strings.Split(str, "-") fmt.Println(str2) fmt.Printf("%T", str2) }[ABC XYZ XXCHENG] []string -
是否包含字串
使用
strings.Contains函数func Contains(s, substr string) boolfunc Test_B_4(t *testing.T) { str := "ABC-XYZ-XXCHENG" isContain := strings.Contains(str, "XYZ") isContain2 := strings.Contains(str, "China") fmt.Println(isContain) fmt.Println(isContain2) fmt.Printf("%T", isContain) }true false bool -
前缀 or 后缀 判断
-
strings.HasPrefix前缀func HasPrefix(s, prefix string) bool { return len(s) >= len(prefix) && s[0:len(prefix)] == prefix } -
strings.HasSuffix后缀func HasSuffix(s, suffix string) bool { return len(s) >= len(suffix) && s[len(s)-len(suffix):] == suffix }
func Test_B_5(t *testing.T) { str := "ABC-XYZ-XXCHENG" hasPrefix := strings.HasPrefix(str, "ABC") hasPrefix2 := strings.HasPrefix(str, "WWW") hasSuffix := strings.HasSuffix(str, "XXCHENG") hasSuffix2 := strings.HasSuffix(str, "WWW") fmt.Println(hasPrefix, hasPrefix2, hasSuffix, hasSuffix2) fmt.Printf("%T,%T,%T,%T", hasPrefix, hasPrefix2, hasSuffix, hasSuffix2) }true false true false bool,bool,bool,bool -
-
字串首次出现位置
-
strings.Index从头开始找func Index(s, substr string) int -
strings.LastIndex从尾开始找func LastIndex(s, substr string) int
func Test_B_6(t *testing.T) { str := "ABC-XYZ-WWW-CCTV-COM-XYZ-XXCHENG" a := strings.Index(str, "XYZ") b := strings.Index(str, "QQQ") c := strings.LastIndex(str, "XYZ") d := strings.LastIndex(str, "QQQ") fmt.Println(a, b, c, d) fmt.Printf("%T,%T,%T,%T", a, b, c, d) }4 -1 21 -1 int,int,int,int -
-
合并字符串数组
func Test_B_7(t *testing.T) { arr := []string{"ABC", "XYZ", "XXCHENG", "CCTV"} str := strings.Join(arr, "-") str2 := strings.Join(arr, "~") fmt.Println(str) fmt.Println(str2) }ABC-XYZ-XXCHENG-CCTV ABC~XYZ~XXCHENG~CCTV
-
-
字符
Go语言有两种字符:byte型,代表一个ASCII码,等同于uint;rune型,代表一个UTF-8字符,等同于int32;
func Test_B_8(t *testing.T) { a := 'Z' b := '中' var c byte = 65 var d rune = b fmt.Printf("%v,%T\n", a, a) fmt.Printf("%v,%T\n", b, b) fmt.Printf("%v,%T\n", c, c) fmt.Printf("%v,%T", d, d) }90,int32 20013,int32 65,uint8 20013,int32因为这两种的字符长度不一样,在我们自己遍历字符串时需要注意出现乱码的问题
func Test_B_9(t *testing.T) { str := "xxcheng小小程日记" for i := 0; i < len(str); i++ { fmt.Printf("ascii:%d,char:%c\t", str[i], str[i]) if i%2 == 1 { fmt.Printf("\n") } } fmt.Println("----------") }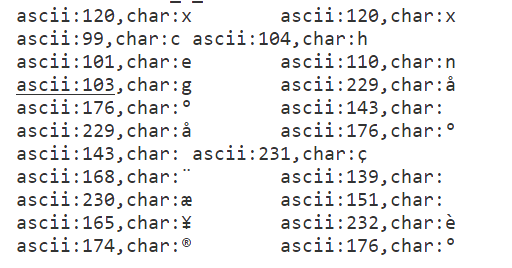
这时候可以使用系统自带的
rangefunc Test_B_10(t *testing.T) { str := "xxcheng小小程日记" for i, c := range str { fmt.Printf("ascii:%d,char:%c\t", c, c) if i%2 == 1 { fmt.Printf("\n") } } fmt.Println("----------") }ascii:120,char:x ascii:120,char:x ascii:99,char:c ascii:104,char:h ascii:101,char:e ascii:110,char:n ascii:103,char:g ascii:23567,char:小 ascii:23567,char:小 ascii:31243,char:程 ascii:26085,char:日 ascii:35760,char:记 ----------rune表示一个UTF-8字符,底层由byte数组组成-
修改字符串中的字符
先将字符串转为
[]byte或者[]rune,修改完之后在重新转为字符串。无论哪种转换,都会重新分配内存,并复制字节数组。,不再是原来的字符串了。func Test_B_12(t *testing.T) { str := "xxcheng" str2 := "小小程日记" str_byteArr := []byte(str) str_byteArr[2] = 'W' str_RuneArr := []rune(str2) str_RuneArr[2] = '小' str = string(str_byteArr) str2 = string(str_RuneArr) fmt.Println(str) fmt.Println(str2) }xxWheng 小小小日记
-
数组
-
切片
-
特点
- 长度可变;
- 切片是引用类型,它不是数组或数组指针,但是底层基于数组和指针实现;
- 初始化时需要分配内存
-
初始化
func Test_B_14(t *testing.T) { arr := [6]int{7, 8, 9, 10} slice := make([]int, 3, 6) slice2 := []int(arr[0:3]) slice3 := []int{7, 8, 9} fmt.Println(slice, len(slice), cap(slice)) fmt.Println(slice2, len(slice2), cap(slice2)) fmt.Println(slice3, len(slice3), cap(slice3)) }[0 0 0] 3 6 [7 8 9] 3 6 [7 8 9] 3 3 -
通过数组的初始化的影响
对元素的修改同时也会修改数组
func Test_B_15(t *testing.T) { arr := [6]int{7, 8, 9, 10} slice := []int(arr[0:3]) slice[1] = 666 arr[2] = 888 fmt.Println(arr, len(arr), cap(arr)) fmt.Println(slice, len(slice), cap(slice)) fmt.Println("----------") slice = append(slice, 999) fmt.Println(arr, len(arr), cap(arr)) fmt.Println(slice, len(slice), cap(slice)) fmt.Println("----------") slice = append(slice, 111, 222, 333, 444, 555) fmt.Println(arr, len(arr), cap(arr)) fmt.Println(slice, len(slice), cap(slice)) }[7 666 888 10 0 0] 6 6 [7 666 888] 3 6 ---------- [7 666 888 999 0 0] 6 6 [7 666 888 999] 4 6 ---------- [7 666 888 999 0 0] 6 6 [7 666 888 999 111 222 333 444 555] 9 12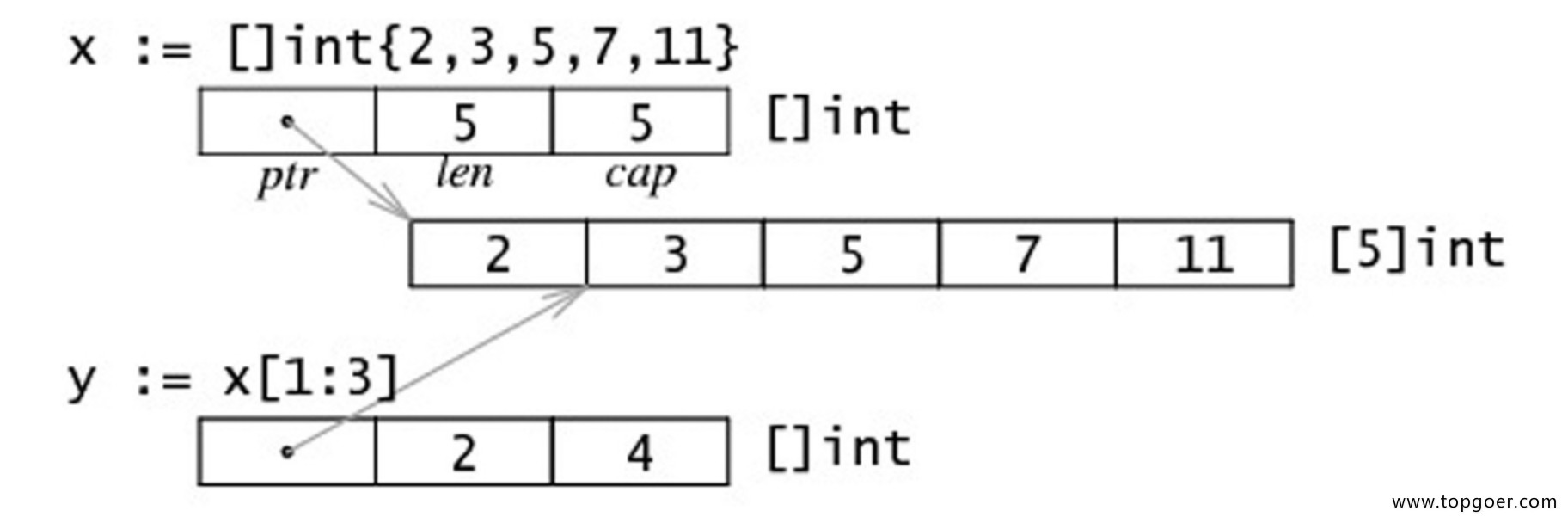
-
对索引的操作
约定切片数据类型为
[]T-
slice[n]获取索引为
n的值,返回值类型Tslice := []int{111, 222, 333, 444, 555, 666, 777, 888, 999} a := slice[3] fmt.Printf("%v,%T", a, a)444,int -
slice[:]相当于复制操作,
slice2:=slice,返回值类型[]Tslice := []int{111, 222, 333, 444, 555, 666, 777, 888, 999} a := slice[:] a[1] = 987 fmt.Printf("%v,%T,%d\n", a, a, cap(a)) fmt.Printf("%v,%T,%d", slice, slice, cap(slice))[111 987 333 444 555 666 777 888 999],[]int,9 [111 987 333 444 555 666 777 888 999],[]int,9 -
slice[n:]获取从
n开始获取到最后子切片,返回值为[]Tslice := []int{111, 222, 333, 444, 555, 666, 777, 888, 999} a := slice[2:] fmt.Printf("%v,%T,%d\n", a, a, cap(a))[333 444 555 666 777 888 999],[]int,7 -
slice[:n]获取从
0开始获取到n-1的子切片,返回值为[]Tslice := []int{111, 222, 333, 444, 555, 666, 777, 888, 999} a := slice[:2] fmt.Printf("%v,%T,%d\n", a, a, cap(a))[111 222],[]int,9 -
slice[x:y]获取从
x开始获取到y-1的子切片,返回值为[]Tslice := []int{111, 222, 333, 444, 555, 666, 777, 888, 999} a := slice[2:4] fmt.Printf("%v,%T,%d\n", a, a, cap(a))[333 444],[]int,7 -
slice[x:y:z]获取从
x开始获取到y-1的子切片,z>=y,返回值为[]T,cap为z-x,默认情况下,z缺省的值为原切片的cap-xslice := []int{111, 222, 333, 444, 555, 666, 777, 888, 999} a := slice[3:6:7] fmt.Printf("%v,%T,%d\n", a, a, cap(a))[444 555 666],[]int,4
-
-
-
参考链接
本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。